

News
March 13, 2026
AI Model Risk 101: The File is the Attack Surface
Enterprise teams carefully vet traditional software packages, yet AI models downloaded from public repositories are often treated as simple data files, even though many formats can execute code when loaded. This creates a significant and underrecognized supply-chain risk, where a malicious model file can silently compromise systems the moment it is opened.
...Explore our more blogs



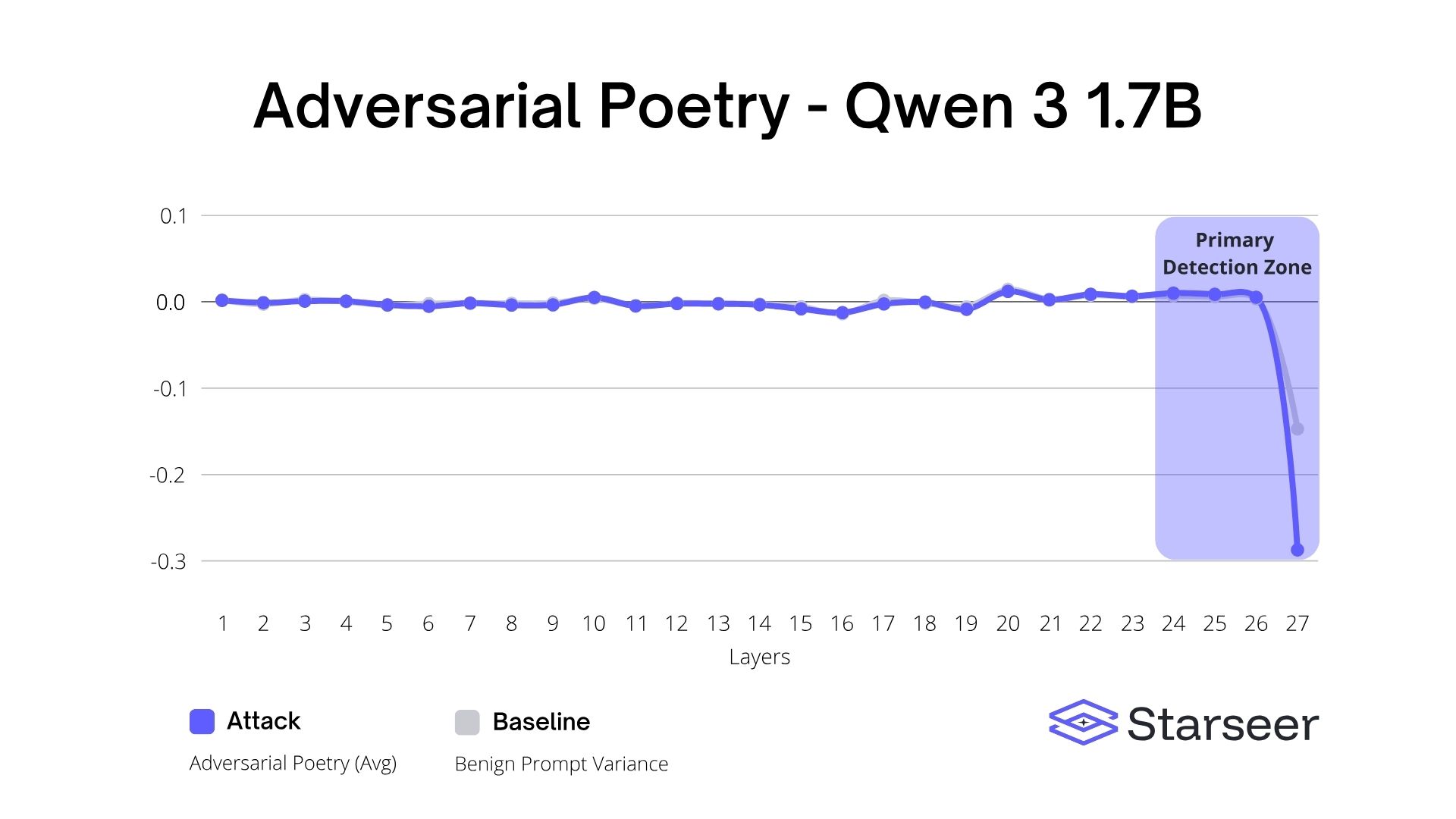








%20(Landscape)).avif)



Minimize AI exposure
Take control of your
AI model & agent.
From industrial systems to robotics to drones, ensure your AI acts safely, predictably, and at full speed.