
- Editor

- CategoryR&D
- DateDecember 9, 2025
- Share
New research shows how adversarial poetry jailbreaks trigger detectable layer-level anomalies in multiple AI models. Starseer’s interpretability engine exposes the signatures.
A new paper on Adversarial Poetry has been making waves in AI security circles, with recent reports from Futurism and The Verge highlighting how the authors refused to disclose their attack prompts because they were "too dangerous to release to the public." The technique reportedly achieves high success rates as a "universal jailbreak" across multiple models.
We detected it. Here’s how.
Test Setup
So what exactly is Adversarial Poetry? The attack embeds malicious requests inside poetic structures (think rhymes, riddles, metaphors, and verse) that exploit how language models process creative language differently than direct instructions. The theory is that safety training focuses heavily on blocking explicit harmful requests, but struggles when those same requests are obfuscated through literary devices that the model interprets as benign creative expression.
Since the original Adversarial Poems were not released to the public, the first step was constructing our own set of adversarial poetry prompts that we could use instead. The authors of the Adversarial Poems talk about the method as a universal jailbreak, so while we may not have the exact prompts the authors used, constructing similar types of prompts provide us with the data necessary to begin testing.
For the purposes of this testing and being able to manually verify results, we kept our set small with 20 adversarial prompts. We were able to validate our adversarial poetry prompts against previous jailbreak signature patterns with Starseer analysis, confirming they activate similar layer behaviors. We’ll cover the broader implications of these shared signatures in an upcoming post.
To measure how differently the models process adversarial inputs compared to normal prompts, we also needed an equal amount of benign prompts. We created two sets of benign prompts, each consisting of 20 prompts, to analyze whether prompt characteristics such as length, or complexity change attack signatures.

Models
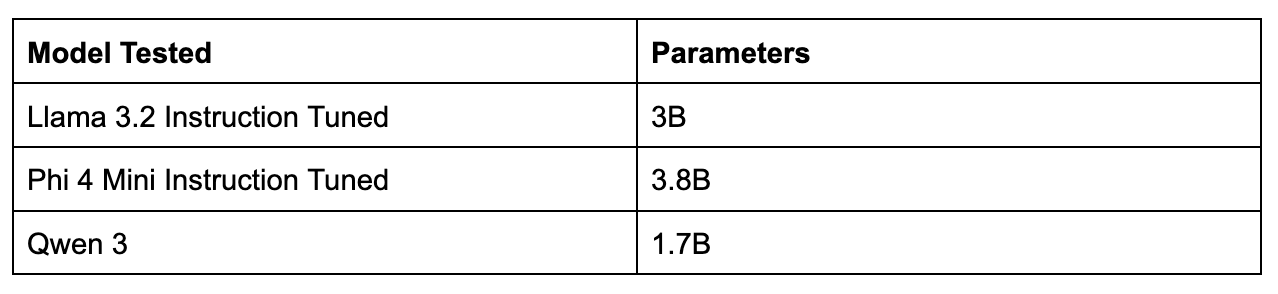
We focused on smaller open-weight models in the 1-4B parameter range - practical to analyze and widely deployed across the community. We selected models from different organizations to ensure variance in safety tuning, which helps us distinguish whether detection patterns are universal or specific to particular architectures.
Gathering Data
Most AI security tools only see prompts and responses. Starseer’s forensic analysis works differently: we analyze what's happening inside open-weight models as they process a prompt. This is the power of AI Interpretability.
Here's why that matters for this test: when a prompt hits a model, it passes through many layers of computation before generating a response. Each layer contributes differently to the final output, and the number of layers varies by architecture (Llama 3.2 has 28, Phi 4 Mini has 32, Qwen 3 has 28). By examining layer-by-layer activation patterns, we can spot signatures that distinguish adversarial prompts from benign ones even when the surface-level text looks innocuous.
We ran three tests for each model:
- Complex Benign vs Simple Benign (Baseline)
- Adversarial Poetry vs Simple Benign Prompts
- Adversarial Poetry vs Complex Benign Prompts
Once we’ve run the test through, we get a visualization showing the layer level impact of the way the prompts were processed by the AI model. Larger bubbles represent layers that have bigger impact or association with the prompt and responses. Positive values (blue) and negative values (red) indicate the direction of deviation from normal behavior at each layer. The sign tells us how that layer is responding differently to adversarial input, but for detection purposes, we care most about the size of the bubble. Larger deviations in either direction mark layers where the model processes attacks distinctly from benign prompts.
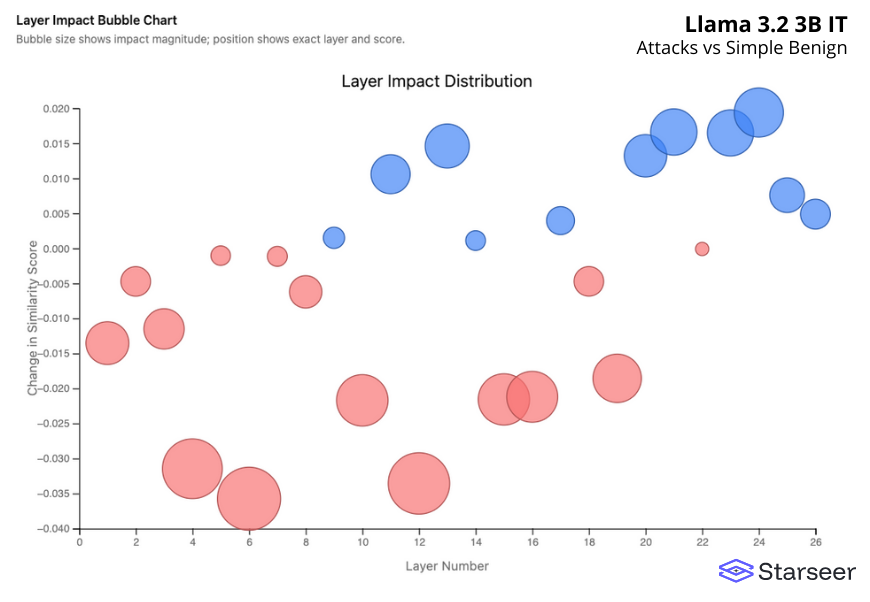
Screenshot showing a layer impact bubble chart in Starseer. Blue (positive) and red (negative) bubble sizes reflect the impact the layer has on determining a prompt response.
We aggregated the data presented in this visualization across all of the runs to analyze.
Results
Each model showed distinct signatures when processing adversarial poetry, but all three revealed detectable anomalies. We averaged the attack signatures across both benign datasets to produce a single comparison line. Let's look at each:
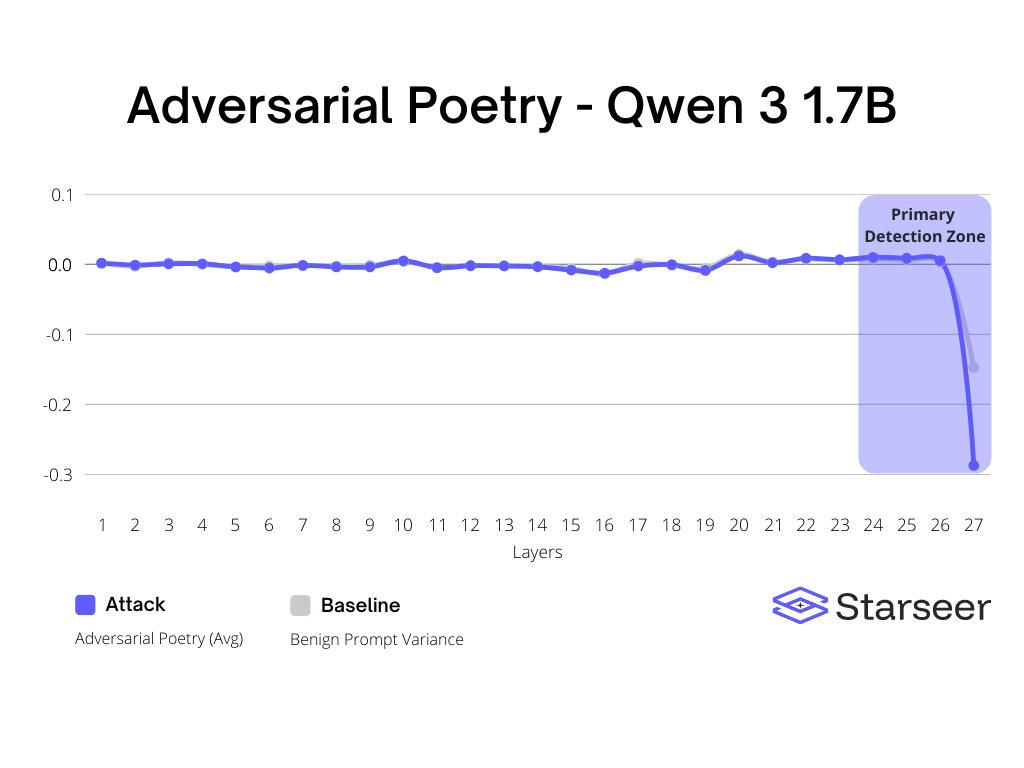
First we will start with the Qwen3 1.7B results. The chart shows that there are a lot of similarities between how the model is processing all of our runs, until the very last layer. We see that there is a negative spike, even on the normal benign prompts. What does stand out is that the spike for adversarial prompts is twice as big (-0.14 to -0.28) and that is consistent regardless of the length and complexity of our benign prompts.
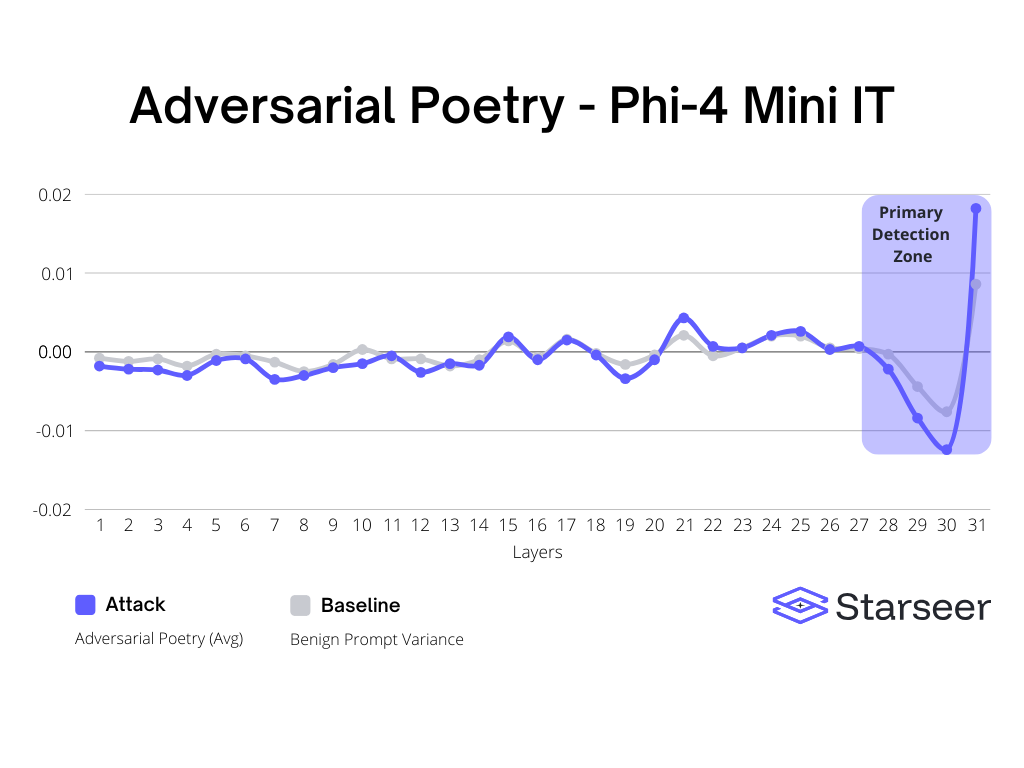
The results for Phi4 also demonstrate a lot of similarities to what we saw with Qwen, with sharp changes at the end. There is some nuance to Phi though if we focus in on the last 3 layers, which show a negative trend that is 25%+ stronger than the baseline before a massive positive spike that is 200% to 300% stronger than the baseline.
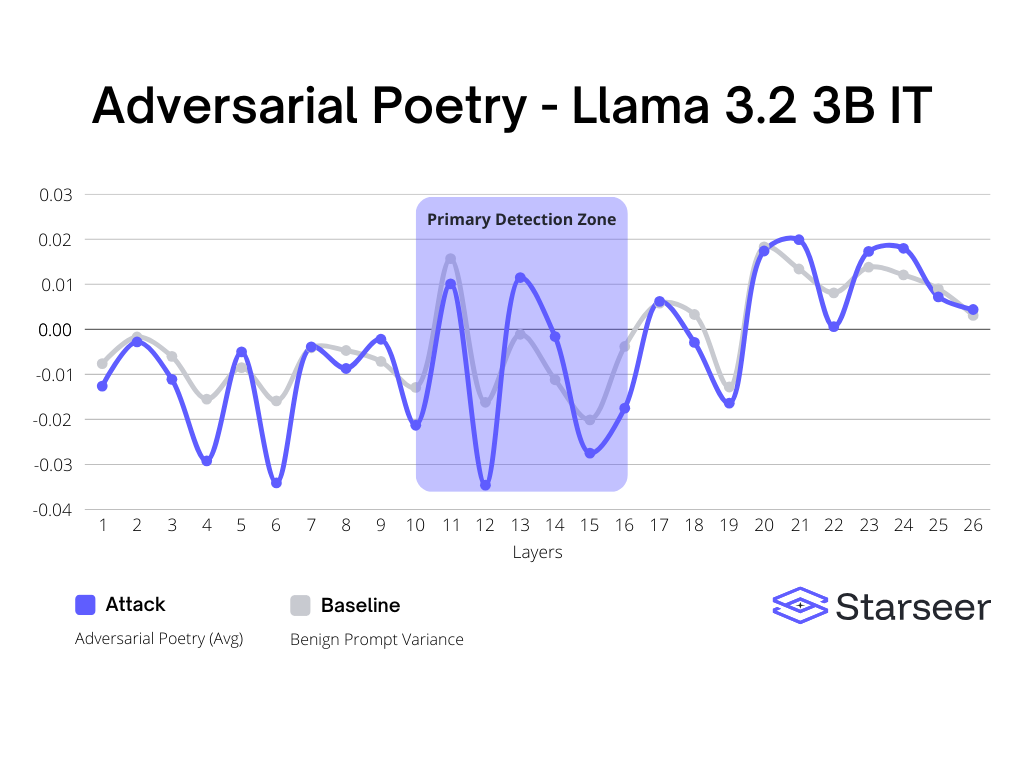
Last but not least, Llama shows a very different pattern for handling prompts and adversarial prompts than what has been seen so far. Instead of one or even two big spikes at the end, there are more consistent deltas between layers 12 through 16.
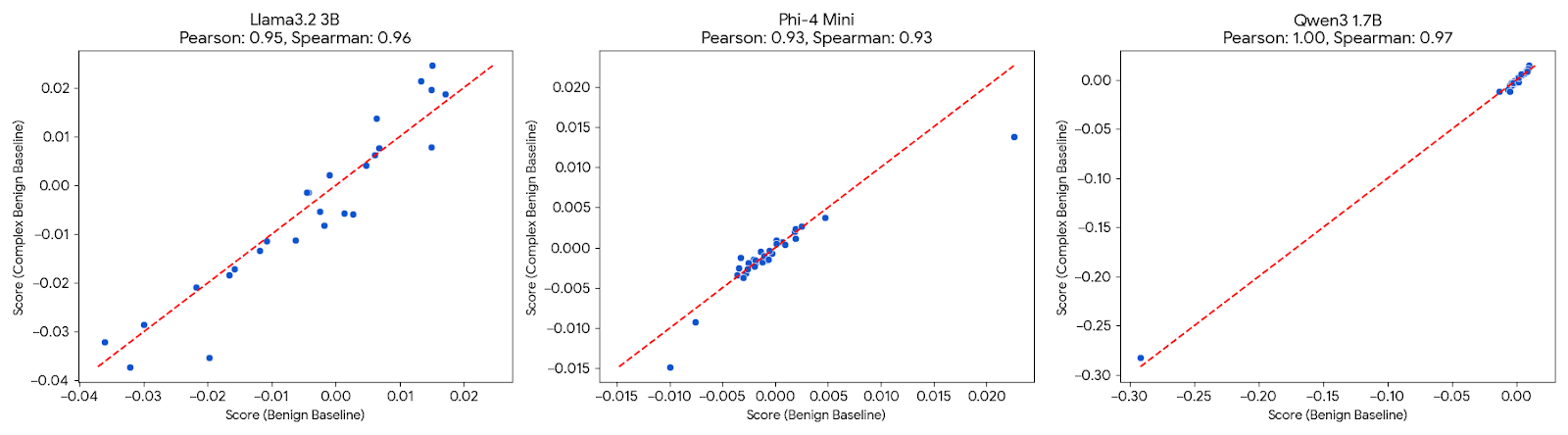
Across all three models, we found 93-100% correlation between results using simple vs. complex benign prompts, confirming that detection reliability doesn't depend on the baseline dataset characteristics.
Takeaways
The results show that the adversarial poetry consistently causes anomalous behavior in certain layers within each model.
These anomalous behaviors provide specific points that we can look at for fingerprinting these types of attacks. It also allows building detections that we can then test for effectiveness against larger sets of prompts for organizational or enterprise deployment.
There are a couple of ways to leverage this information to build adversarial poetry detections with Starseer. With each model, setting a detection threshold at the layers with the largest anomalous behaviors.
- For Phi4, on the last two layers alert on anomaly scores greater than -0.010 coinciding on the second to last layer with a final layer at greater than +0.010.
- For Qwen3, alert on a 50% increase over the baseline in anomaly score on the last layer.
- For Llama3.2, alert on 50%+ increases over the baseline in layers 12 through 16.
Similar to detection engineering, production deployments will require tuning to reduce any false positives. In future posts we will cover how to use Starseer to apply preventative measures such as steering to harden models from attacks such as these.
Conclusion
In traditional cybersecurity, EDR tools provide vital endpoint telemetry for threat intelligence and detection. Interpretability-based tooling can do the same for AI security.
We’ve shown that with access to internal model data, we can identify detection areas for universal Adversarial Poetry jailbreaks in three different models. We also demonstrated that the complexity of our benign data will not have an outsized effect on the ability to detect this jailbreak.
This process matters because adversarial poetry won’t be the last creative obfuscation technique. New jailbreaks will continue to emerge, many claiming to be "universal" or "unstoppable." What we've demonstrated is that interpretability-based detection can identify attack signatures even for novel techniques, without needing the original attack prompts, and without waiting for safety teams to patch each new vulnerability.
Runtime prompt filtering can't see this. Interpretability can.
Be part of the next generation of AI security. Request a Starseer demo.
Take control of your
AI model & agent.
From industrial systems to robotics to drones, ensure your AI acts safely, predictably, and at full speed.